- Глубокое погружение в ROC-AUC
- Теория ROC-кривой
- Что такое ROC-кривая?
- Что значит синяя пунктирная линия на графике?
- Как выбрать оптимальную точку на кривой ROC?
- Почему площадь под кривой ROC – хорошая метрика для оценки модели классификации?
- Какое значение AUC является приемлемым для модели классификации?
- Как рассчитать AUC и построить ROC-кривую в Python?
- Площадь под кривой ROC или область под кривой PR для несбалансированных данных?
- Метрики оценки машинного обучения в R
- Метрики оценки модели в R
- Метрики для оценки алгоритмов машинного обучения
- Точность и каппа
- RMSE и R ^ 2
- Площадь под кривой ROC
- Логарифмическая потеря
- Резюме
- Следующий шаг
- 📸 Видео
Видео:Площади 12Скачать

Глубокое погружение в ROC-AUC
Я думаю, что большинство людей слышали о ROC-кривой или о AUC (площади под кривой) раньше. Особенно те, кто интересуется наукой о данных. Однако, что такое ROC-кривая и почему площадь под этой кривой является хорошей метрикой для оценки модели классификации?
Видео:ROC-AUC, ROC-CURVE, ROC-КРИВАЯ | МЕТРИКИ КЛАССИФИКАЦИИСкачать

Теория ROC-кривой
Полное название ROC — Receiver Operating Characteristic (рабочая характеристика приёмника). Впервые она была создана для использования радиолокационного обнаружения сигналов во время Второй мировой войны. США использовали ROC для повышения точности обнаружения японских самолетов с помощью радара. Поэтому ее называют рабочей характеристикой приемника.
AUC или area under curve — это просто площадь под кривой ROC. Прежде чем мы перейдем к тому, что такое ROC-кривая, нужно вспомнить, что такое матрица ошибок.
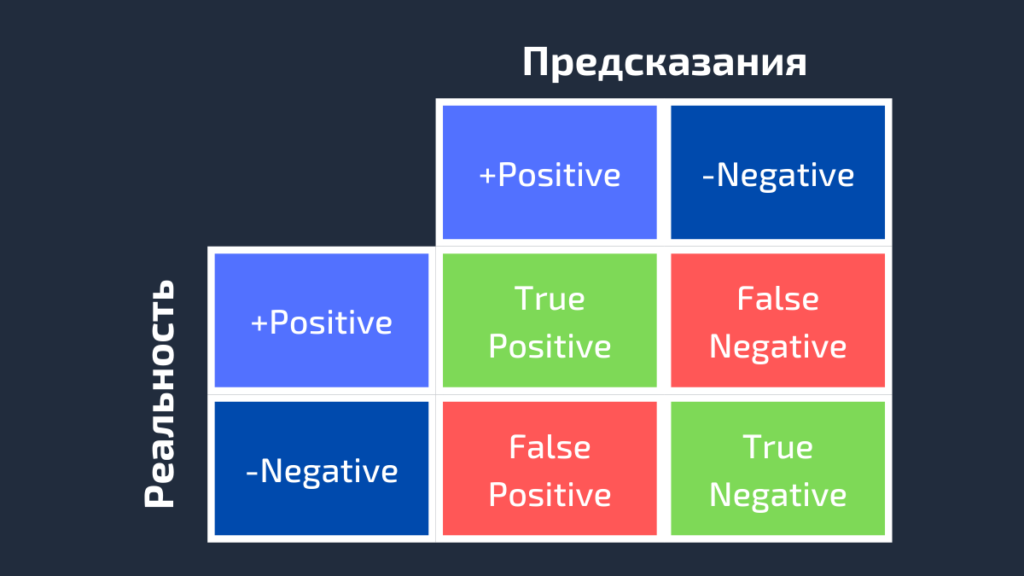
Как видно из рисунка выше, матрица ошибок — это комбинация вашего прогноза (1 или 0) и фактического значения (1 или 0). В зависимости от результата предсказания и того, корректна ли была проведена классификация, матрица разделена на 4 части. Например, true positive (истинно положительный) результат — это количество случаев, в которых вы правильно классифицируете семпл как положительный. А false positive (ложноположительный) — это число случаев, в которых вы ошибочно классифицируете семпл как положительный.
Матрица ошибок содержит только абсолютные числа. Однако, используя их, мы можем получить множество других метрик, основанных на процентных соотношениях. True Positive Rate (TPR) и False Positive Rate (FPR) — две из них.
True Positive Rate (TPR) показывает, какой процент среди всех positive верно предсказан моделью.
TPR = TP / (TP + FN).
False Positive Rate (FPR): какой процент среди всех negative неверно предсказан моделью.
FPR = FP / (FP + TN).
Хорошо, давайте теперь перейдем к кривой ROC!
Видео:PR-AUC, PR-CURVE, PR-КРИВАЯ, PRECISION RECALL КРИВАЯ | МЕТРИКИ КЛАССИФИКАЦИИСкачать

Что такое ROC-кривая?
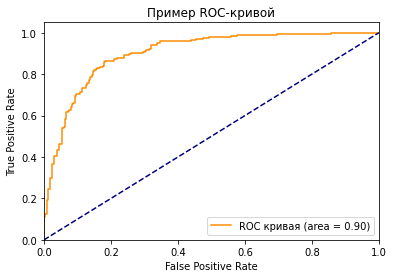
Как вы можете видеть на графике, кривая ROC — это просто отношение TPR к FPR. Теперь вам все понятно, в заключение…
Поверили?
Если серьезно, вы можете прочитать намного больше информации из диаграммы. Первый вопрос, который я хочу здесь обсудить: у нас же есть только один набор TPR, FPR, посчитанный на основе сделанных моделью предсказаний. Так откуда взялось такое количество точек для построения целого графика?
Все следует из того, как работает модель классификации. Когда вы строите классификационную модель, такую как дерево решений, и хотите определить, будут ли акции расти в цене или падать на основе входных данных. Модель сначала рассчитает вероятность увеличения или уменьшения, используя предоставленные вами исторические данные. После этого, основываясь на пороговом значении, она решит, будет ли результат увеличиваться или уменьшаться.
Да, ключевое слово здесь — порог. Разные пороговые значения создают разные TPR и FPR. Они представляют те самые точки, что образуют кривую ROC. Вы можете выбрать «Увеличение» в качестве предсказания модели, если полученная на основе исторических данных вероятность роста акций больше 50%. Также можете изменить пороговое значение и отобразить «Увеличение», только если соответствующая вероятность больше 90%. Если вы установите 90% порог вместо 50%, вы будете более уверены в том, что выбранные для «Увеличения» акции действительно вырастут. Но так вы можете упустить некоторые потенциально выгодные варианты.
Видео:Геометрический смысл определенного интеграла (2)Скачать

Что значит синяя пунктирная линия на графике?
Как мы знаем, чем больше площадь под кривой (AUC), тем лучше классификация. Идеальная или наилучшая кривая — это вертикальная линия от (0,0) до (0,1), которая тянется до (1,1). Это означает: модель всегда может различить положительные и отрицательные случаи. Однако, если вы выбираете класс случайным образом для каждого семпла, TPR и FPR должны увеличиваться с одинаковой скоростью. Синяя пунктирная линия показывает кривую TPR и FPR при случайном определении positive или negative для каждого случая. Для этой диагональной линии площадь под кривой (AUC) составляет 0.5.
Что произойдет с TPR, FPR и ROC-кривой, если изменить пороговое значение?
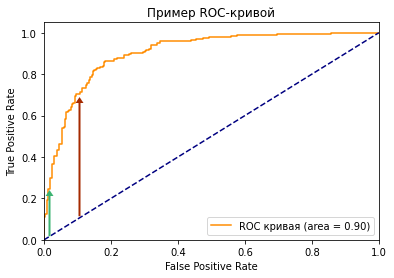
Посмотрите на две точки на ROC-кривой. Зеленая точка имеет очень высокий порог, это означает, что только если вы уверены на 99%, можете классифицировать случай как positive. Красная точка имеет относительно более низкий порог. Это означает, что вы можете классифицировать случай как positive, если вы уверены на 90%.
Как изменяются TPR и FPR при движении от зеленой точки к красной?
И TPR, и FPR увеличиваются. Когда вы уменьшаете порог, модель будет определять больше положительных случаев. Таким образом, TP увеличивается, как и TP/(TP + FN). С другой стороны, вы неизбежно ошибочно классифицируете некоторые отрицательные случаи как положительные из-за снижения порога, и поэтому FP и FP/(FP + TN) также увеличиваются.
Мы видим, что TPR и FPR положительно коррелируют. Вам нужно балансировать между максимальным охватом positive случаев и минимизацией неправильной классификации negative случаев.
Видео:Найти площадь СУПЕРЭЛЛИПСА* (Кривая Ламе см.описание)Скачать

Как выбрать оптимальную точку на кривой ROC?
Трудно определить оптимальную точку, потому что нужно выбрать наиболее подходящее пороговое значение, учитывая сферу применения модели. Однако общее правило — максимизировать разницу (TPR-FPR), которая на графике представлена вертикальным расстоянием между оранжевой и синей пунктирной линией.
Видео:Криволинейная трапеция и ее площадь. Практическая часть. 11 класс.Скачать
Почему площадь под кривой ROC – хорошая метрика для оценки модели классификации?
Хорошая метрика модели машинного обучения должна отображать истинную и постоянную способность модели к прогнозированию. Это означает, что, если я изменю тестовый набор данных, он не должен давать другой результат.
ROC-кривая учитывает не только результаты классификации, но и вероятность предсказания всех классов. Например, если результат корректно классифицирован на основе 51% вероятности, то он, скорее всего, будет классифицирован неверно, если вы воспользуетесь другим тестовым датасетом. Кроме того, ROC-кривая также учитывает эффективность модели при различных пороговых значениях. Она является комплексной метрикой для оценки того, насколько хорошо разделяются случаи в разных группах.
Видео:ROC AUC и GiniСкачать

Какое значение AUC является приемлемым для модели классификации?
Как я показал ранее, для задачи двоичной классификации при определении классов случайным образом, вы можете получить 0.5 AUC. Следовательно, если вы решаете задачу бинарной классификации, разумное значение AUC должно быть > 0.5. У хорошей модели классификации показатель AUC > 0.9, но это значение сильно зависит от сферы ее применения.
Видео:Доступное объяснение ROC и AUC!Скачать

Как рассчитать AUC и построить ROC-кривую в Python?
Если вы просто хотите рассчитать AUC, вы можете воспользоваться пакетом metrics библиотеки sklearn (ссылка).
Если вы хотите построить ROC-кривую для результатов вашей модели, вам стоит перейти сюда.
Вот код для построения графика ROC, который я использовал в этой статье.
Видео:Сергей Наговицын - Без проституток и воровСкачать

Площадь под кривой ROC или область под кривой PR для несбалансированных данных?
У меня есть некоторые сомнения по поводу того, какую меру эффективности использовать: область под кривой ROC (TPR как функция FPR) или область под кривой точности-отзыва (точность как функция отзыва).
Мои данные несбалансированы, то есть количество отрицательных экземпляров намного больше, чем положительных.
Я использую выходной прогноз Weka, пример:
И я использую библиотеки pROC и ROCR r.
Вопрос довольно расплывчатый, поэтому я собираюсь предположить, что вы хотите выбрать подходящий показатель производительности для сравнения разных моделей. Для хорошего обзора ключевых различий между кривыми ROC и PR вы можете обратиться к следующему документу: «Отношения между точным восстановлением и кривыми ROC » Дэвиса и Гоудрича .
Процитирую Дэвиса и Гоадрича:
Однако при работе с сильно искаженными наборами данных кривые Precision-Recall (PR) дают более информативную картину производительности алгоритма.
F P ‘ role=»presentation»> F P
Кривые точного возврата лучше выделить различия между моделями для сильно несбалансированных наборов данных. Если вы хотите сравнить разные модели в несбалансированных настройках, область под кривой PR, вероятно, будет демонстрировать большие различия, чем область под кривой ROC.
Тем не менее, кривые ROC встречаются гораздо чаще (даже если они менее подходят). В зависимости от вашей аудитории, кривые ROC могут быть лингва франкой, поэтому их использование, вероятно, является более безопасным выбором. Если одна модель полностью доминирует над другой в пространстве PR (например, всегда имеет более высокую точность во всем диапазоне отзыва), она также будет доминировать в пространстве ROC. Если кривые пересекаются в одном пространстве, они также пересекаются в другом. Другими словами, основные выводы будут одинаковыми независимо от того, какую кривую вы используете.
Бесстыдная реклама . В качестве дополнительного примера вы можете взглянуть на одну из моих работ, в которой я сообщаю как кривые ROC, так и PR в несбалансированном виде. Рисунок 3 содержит кривые ROC и PR для идентичных моделей, четко показывая разницу между ними. Чтобы сравнить площадь под PR и площадь под ROC, вы можете сравнить таблицы 1-2 (AUPR) и таблицы 3-4 (AUROC), где вы можете видеть, что AUPR показывает гораздо большие различия между отдельными моделями, чем AUROC. Это еще раз подчеркивает пригодность кривых PR.
Видео:Лекция. Нейронная детекция объектов. Основы.Скачать

Метрики оценки машинного обучения в R
Дата публикации 2016-02-29
Какие показатели вы можете использовать для оценки ваших алгоритмов машинного обучения?
В этом посте вы узнаете, как вы можете оценить свои алгоритмы машинного обучения в R, используя ряд стандартных метрик оценки.

Видео:07.03.2023 Лекция 10. Вычисление площади и объема. Понятия кривой и путиСкачать

Метрики оценки модели в R
Существует множество различных метрик, которые вы можете использовать для оценки алгоритмов машинного обучения в R.
Когда вы используете каретку для оценки ваших моделей, используются метрики по умолчанию:точностьдля задач классификации иRMSEдля регрессии. Но Caret поддерживает ряд других популярных метрик оценки.
В следующем разделе вы ознакомитесь с каждым из показателей оценки, предоставленных компанией Caret. Каждый пример содержит полный пример, который вы можете скопировать и вставить в свой проект и адаптировать к вашей проблеме.
Обратите внимание, что этот пост предполагает, что вы уже знаете, как интерпретировать эти другие метрики. Не волнуйтесь, если они новички для вас, я предоставил несколько ссылок для дальнейшего чтения, где вы можете узнать больше.
Видео:Метрики точности моделей в машинном обучении: precision, recall, ROC AUC - Дмитрий Хизбуллин// PASVСкачать

Метрики для оценки алгоритмов машинного обучения
В этом разделе вы узнаете, как вы можете оценить алгоритмы машинного обучения, используя ряд различных общих метрик оценки.
В частности, этот раздел покажет вам, как использовать следующие метрики оценки с пакетом каретки в R:
- Точность и каппа
- RMSE и R ^ 2
- ROC (AUC, Чувствительность и Специфичность)
- LogLoss
Точность и каппа
Это метрики по умолчанию, используемые для оценки алгоритмов в двоичных и мультиклассовых классификационных наборах данных в карете.
точностьпроцент правильно классифицирует экземпляры из всех экземпляров. Это более полезно для бинарной классификации, чем для задач мультиклассовой классификации, потому что может быть не совсем понятно, как именно точность разбивается на эти классы (например, вам нужно углубиться в матрицу путаницы).Узнайте больше о точности здесь,
Каппаили Каппа Коэна похожа на точность классификации, за исключением того, что она нормализована на основе случайных случайностей в вашем наборе данных. Это более полезная мера для использования в задачах, которые имеют дисбаланс в классах (например, 70-30 разделение для классов 0 и 1, и вы можете достичь точности 70%, прогнозируя все экземпляры для класса 0).Узнайте больше о Каппа здесь,
В приведенном ниже примере используется набор данных диабета индейцев Пима. Он имеет класс разбивки от 65% до 35% для отрицательных и положительных результатов.
Запустив этот пример, мы можем увидеть таблицы точности и каппы для каждого оцениваемого алгоритма машинного обучения. Это включает в себя средние значения (слева) и стандартные отклонения (отмеченные как SD) для каждой метрики, взятые по совокупности перекрестных проверок и испытаний.
Вы можете видеть, что точность модели составляет приблизительно 76%, что на 11 процентных пунктов выше базовой точности в 65%, что не очень впечатляет. Каппа с другой стороны показывает примерно 46%, что более интересно.
RMSE и R ^ 2
Это метрики по умолчанию, используемые для оценки алгоритмов регрессионных наборов данных в карете.
RMSEили Корневая средняя квадратичная ошибка — это среднее отклонение прогнозов от наблюдений. Полезно получить общее представление о том, насколько хорошо (или нет) алгоритм работает в единицах выходной переменной.Узнайте больше о RMSE здесь,
R ^ 2Произносится как R Squared или также называется коэффициентом детерминации и обеспечивает меру «правильности соответствия» для прогнозов наблюдений. Это значение между 0 и 1 для неподходящего и идеального соответствия соответственно.Узнайте больше о R ^ 2 здесь,
В этом примере используется длительный набор экономических данных. Выходной переменной является «число занятых». Не ясно, является ли это фактическим счетом (например, в миллионах) или процентом.
Запустив этот пример, мы можем увидеть таблицы RMSE и R Squared для каждого оцениваемого алгоритма машинного обучения. Опять же, вы можете увидеть среднее и стандартные отклонения обеих метрик.
Вы можете видеть, что среднеквадратическое среднеквадратичное значение составляло 0,38 в единицах занятости (какими бы ни были эти единицы). Принимая во внимание, что значение R Square хорошо подходит для данных со значением, очень близким к 1 (0,988).
Площадь под кривой ROC
Метрики ROC подходят только для задач двоичной классификации (например, два класса).
Чтобы рассчитать ROC-информацию, вы должны изменить summaryFunction в вашем trainControl на twoClassSummary. Это позволит рассчитать площадь под кривой ROC (AUROC), также называемой просто площадью под кривой (AUC), чувствительностью и специфичностью.
РПЦна самом деле площадь под кривой ROC или AUC. AUC представляет собой способность модели различать положительные и отрицательные классы. Область 1.0 представляет модель, которая делает все предсказания идеально. Площадь 0,5 представляет модель, как случайную.Узнайте больше о РПЦ здесь,
РПЦ можно разбить на чувствительность и специфику Проблема бинарной классификации — это действительно компромисс между чувствительностью и специфичностью.
чувствительностьистинный положительный показатель также называется отзывом. Это число экземпляров из положительного (первого) класса, которое на самом деле правильно предсказано.
специфичностьтакже называется истинной отрицательной ставкой. Количество экземпляров из отрицательного класса (второго) класса, которые на самом деле были правильно спрогнозированы.Узнайте больше о чувствительности и специфичности здесь,
Здесь вы можете увидеть «хороший», но не «отличный» результат AUC 0,833. Первый уровень принимается за положительный класс, в данном случае «нег» (без возникновения диабета).
Логарифмическая потеря
Логарифмическая потеря или LogLoss используется для оценки двоичной классификации, но она более распространена для алгоритмов классификации нескольких классов. В частности, он оценивает вероятности, оцениваемые алгоритмами.Узнайте больше о потере журнала здесь,
В этом случае мы видим logloss, рассчитанный для задачи классификации мультикласса цветка ириса.
Logloss сводится к минимуму, и мы видим, что оптимальная модель CART имела cp 0.
Видео:Площадь круга. Математика 6 класс.Скачать

Резюме
В этом посте вы обнаружили различные метрики, которые можно использовать для оценки производительности ваших алгоритмов машинного обучения в R с помощью каретки. В частности:
- Точность и каппа
- RMSE и R ^ 2
- ROC (AUC, Чувствительность и Специфичность)
- LogLoss
Вы можете использовать рецепты в этом посте, чтобы оценить алгоритмы машинного обучения в своем текущем или следующем проекте машинного обучения.
Видео:8. МО-1 ФКН: PR-AUC и ROC-AUCСкачать

Следующий шаг
Проработайте пример в этом посте.
- Откройте интерактивную среду R
- Тип скопировать и вставить пример кода выше.
- Не торопитесь и понимайте, что происходит, используйте справку R для ознакомления с функциями.
У вас есть вопросы? Оставьте комментарий, и я сделаю все возможное.
📸 Видео
Длина окружности. Математика 6 класс.Скачать

Как находить площадь любой фигуры? Геометрия | МатематикаСкачать

#24. Метрики качества ранжирования. ROC-кривая | Машинное обучениеСкачать

Лекция 7. Метрики качества классификации. Сергей АртамоновСкачать

✓ Площадь через диагонали | Ботай со мной #122 | Борис ТрушинСкачать

Машинное обучение 1, лекция 5 (дополнение) — метрики качества ранжированияСкачать
